How I Built an Auto-Failover AI Brain with Gemini, Llama & Qwen
How Gemini, Llama 3 and Qwen 2.5 work together to create a resilient multi-agent AI architecture.
Ranajit Dhar
AI Architect & Builder
Introduction
The AI industry is evolving faster than most engineers can track.
Modern AI products are increasingly powered by Large Language Models — Gemini, GPT, Claude, Llama, and Qwen. While these models have dramatically improved software capabilities, they introduce a challenge that most agentic AI architectures ignore until it hits production.
What happens when your primary AI model fails?
A quota limit. A rate limit. A temporary outage. A network disruption.
Most AI applications simply crash. Users see an error screen. The autonomous workflow stops. Trust is lost.
While building YES AI Master Edition, I wanted to solve a fundamentally different problem — not just what the AI can do, but how reliably it can keep doing it at production scale.
How can a multi-agent system continue operating even when its primary intelligence layer becomes unavailable?
That question led me to design a Multi-Brain Auto-Failover Architecture — a self-healing AI operating system built on Gemini 3 Pro, Llama 3, and Qwen 2.5 working in layered failover sequence. This is AI reliability engineering in practice.
What Is YES AI Master Edition?
YES AI Master Edition is not a chatbot.
It is a multi-agent, multi-brain, self-healing AI operating system designed to survive real-world failures without interrupting the user experience. It does not just answer questions — it orchestrates agents, routes intelligence across models, and recovers from failures automatically.
This is what AI orchestration looks like when reliability is the primary design constraint.
At its core, three models operate in a priority chain:
- Gemini 3 Pro — Primary Brain. Handles all reasoning, planning, and agent coordination.
- Llama 3 via Groq — Continuity Brain. Activates instantly when Gemini is unavailable.
- Qwen 2.5 — Survival Brain. The final layer when everything else is down.
The objective is simple: never allow a single model failure to interrupt the user experience.
This is what separates an AI operating system from a simple chatbot wrapper.
The Problem With Most AI Applications
Most AI applications — even sophisticated ones — follow a dangerously fragile architecture:
User
↓
Single AI Model
↓
ResponseThis works perfectly until the model becomes unavailable. And in 2026, with LLM API traffic at all-time highs, every provider experiences downtime, rate limits, and quota exhaustion.
Common failure scenarios include API quota exhaustion, rate limiting, provider downtime, network failures, and invalid request errors. When any of these hit a single-model system:
User
↓
Failed Request
↓
Application CrashThe user loses trust. The product loses credibility. This is the core AI infrastructure problem that most teams do not solve until it is too late.
The Auto-Failover Solution
Instead of depending on a single provider, YES AI uses a layered intelligence architecture — three independent AI models, each with a dedicated role, each ready to take over instantly.
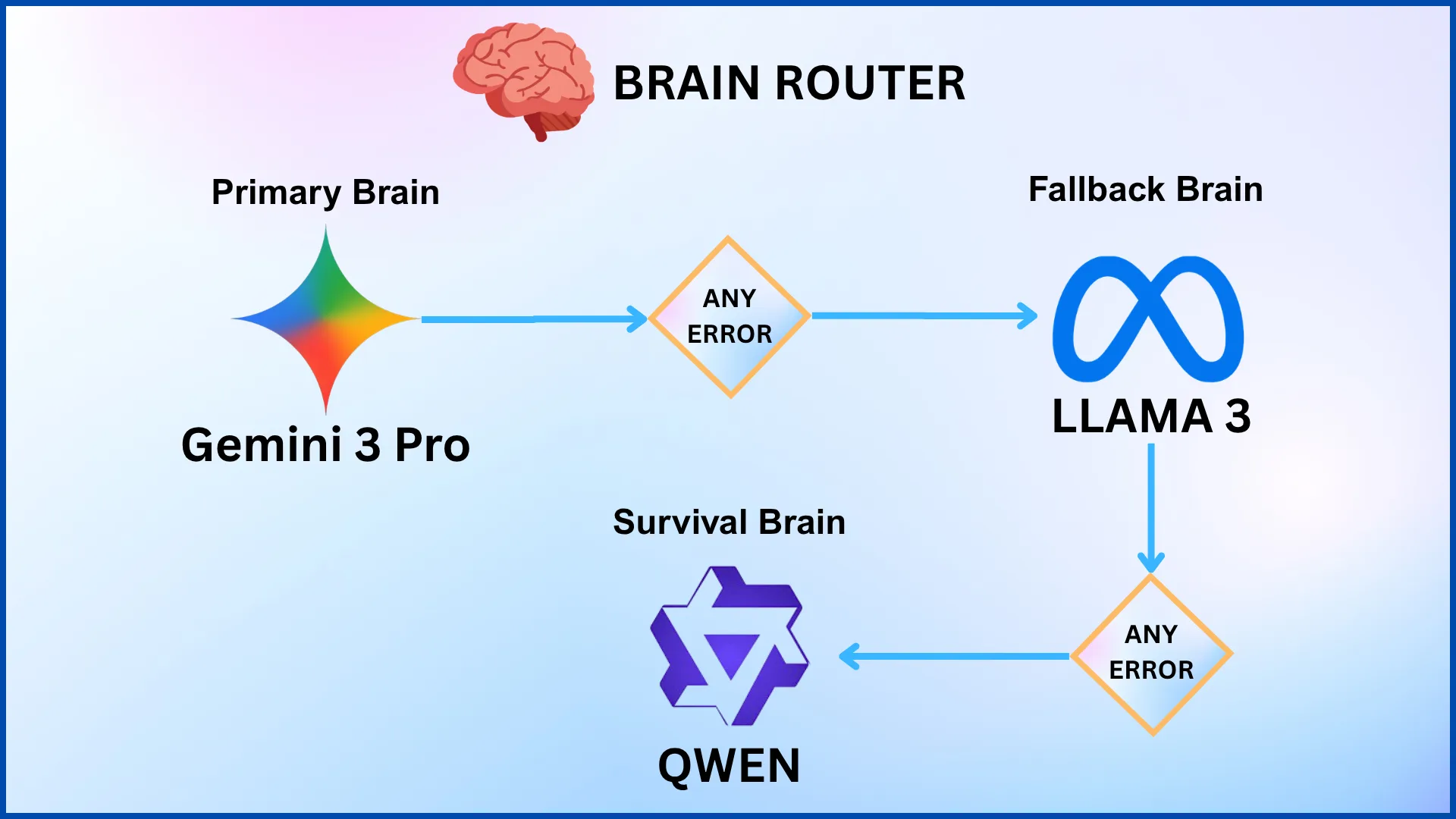
Primary Brain → Gemini 3 Pro
↓
Continuity Brain → Llama 3 (Groq)
↓
Survival Brain → Qwen 2.5This is the core of multi-model AI routing — a technique that is fast becoming the standard for production-grade enterprise AI systems in 2026.
Layer 1 — Gemini 3 Pro (Primary Brain)
Gemini acts as the system's cognitive core. Every request starts here.
Responsibilities: Advanced reasoning, multi-step planning, agent coordination, reflection, and complex problem solving — the full stack of agentic AI capabilities.
The Universal Brain Router always attempts Gemini first. Only on failure does it escalate.
if os.getenv("GOOGLE_API_KEY") and not self.gemini_disabled:
try:
response = model.generate_content(
f"Expert Agent: {prompt}"
)
return response.text, "Gemini 3 Pro"
except Exception:
self.gemini_disabled = TrueThis guarantees the highest quality reasoning whenever Gemini is available — and a graceful exit when it is not.
Layer 2 — Llama 3 via Groq (Continuity Brain)
When Gemini fails, the system does not stop. It does not throw an error. It silently activates Llama 3 via Groq and continues processing in milliseconds — true AI workflow automation at the infrastructure level.
client = Groq(api_key=os.getenv("GROQ_API_KEY"))
completion = client.chat.completions.create(
model="llama-3.3-70b-versatile",
messages=[
{"role": "user", "content": prompt}
]
)Responsibilities: High-speed failover, business continuity, and backup inference at scale.
The user never sees the failure. The autonomous workflow simply continues.
Layer 3 — Qwen 2.5 (Survival Brain)
The final layer exists for worst-case scenarios — when both Gemini and Llama are simultaneously unavailable.
response = client.chat_completion(
model="Qwen/Qwen2.5-7B-Instruct",
messages=[
{"role": "user", "content": prompt}
]
)Responsibilities: Emergency recovery, service survival, and final response generation.
The philosophy is simple — something useful is always better than a crash. This is what self-healing AI looks like at the infrastructure layer.
Circuit Breaker Pattern
One of the most critical AI reliability engineering decisions in YES AI was implementing the Circuit Breaker Pattern.
except Exception:
self.gemini_disabled = TrueOnce a model fails, it is immediately flagged and bypassed for all subsequent requests in the session. This eliminates retry latency, prevents cascading failures, and keeps the multi-agent system responsive even under degraded conditions.
Benefits: Faster recovery, lower latency, better reliability, and a significantly improved user experience — even when the underlying LLM infrastructure is under stress.
High-Level Failover Workflow
User Prompt
↓
Gemini 3 Pro ──── Success? ── YES ──▶ Output
↓ NO
Llama 3 ──────── Success? ── YES ──▶ Output
↓ NO
Qwen 2.5 ──────────────────────────▶ OutputAt every layer, the LLM router asks one question: did this succeed? If yes, return. If no, escalate immediately — no retries, no waiting, no downtime.
Real-World Example
Imagine a founder running a live investor demo on YES AI. Midway through the presentation, Gemini hits its quota limit.
In a traditional single-model AI product:
Gemini → Error 429
Request Failed
Demo Failed
User FrustratedIn YES AI Master Edition with auto-failover architecture:
Gemini → Error 429
Circuit Breaker Activated
↓
Llama 3 Activated
↓
Request Completed SuccessfullyThe founder never knew anything failed. The demo continues. The investor is impressed.
Why Multi-Agent Systems Need Multi-Brain Reliability
The future of AI is agentic — autonomous agents running multi-step workflows, making decisions, calling tools, and operating without constant human supervision.
Organizations in 2026 are now harnessing multiple agents acting together to handle task complexity that was difficult to imagine just a year ago. In this world, a single model failure is not an inconvenience — it is a mission-critical outage.
This is why YES AI combines multi-brain routing, auto-failover logic, circuit breakers, self-healing recovery, and agent swarm coordination into a single unified architecture. Each piece answers one question: what happens when things go wrong?
Technologies Used
AI Models — Gemini 3 Pro, Llama 3 (Groq), Qwen 2.5
Development Stack — Python, Streamlit, Groq API, Google Gemini API, Hugging Face Inference API
Core Concepts — Agentic AI, Multi-Agent Systems, AI Orchestration, LLM Routing, AI Reliability Engineering, Self-Healing Architectures, Circuit Breaker Pattern, Autonomous Agents, AI Failover Architecture, AI Infrastructure, AI Operating System, Enterprise AI Systems
Key Lessons Learned
Single model dependency is dangerous. Every provider eventually fails. AI reliability engineering must be built into the architecture from day one — not added as an afterthought when things break in production.
Users care about outcomes, not providers. They do not care whether Gemini or Llama generated the answer. They care about getting a result. Build autonomous AI systems for that outcome.
Reliability is a competitive advantage. In 2026, where every AI product claims intelligence, dependability is the real differentiator. The best enterprise AI systems are not just smart — they are trustworthy, fault-tolerant, and always available.
Final Thoughts
The future belongs to resilient agentic AI systems.
As AI becomes increasingly integrated into business operations, downtime becomes unacceptable. Users expect AI automation to work — all the time, under any condition, without explanation.
The architecture behind YES AI Master Edition was built around one principle:
Intelligence should never disappear because one model fails.
By combining Gemini, Llama, and Qwen into a layered LLM routing architecture, YES AI can recover, adapt, and continue operating under real-world conditions that would bring most AI products to a complete stop.
The next evolution of AI will not simply be smarter. It will be self-healing, fault-tolerant, multi-agent, and always available.
🔍 SEO Keywords
Agentic AI, Multi Agent AI, AI Architecture, AI Engineer, LLM Routing, AI Orchestration, Gemini 3 Pro, Llama 3, Qwen 2.5, Autonomous Agents, Self-Healing AI, AI Workflow Automation, AI Operating System, AI Infrastructure, AI Reliability Engineering, Enterprise AI Systems, AI Failover Architecture, Multi Model AI, AI Agent Framework, AI Automation, Ranajit Dhar, AI Developer Ranajit Dhar.
👨💻 About The Author
Ranajit Dhar
Commerce Graduate → AI Engineer
Creator of ChayRa AI, TryNext AI, YES AI Master Edition, and multiple agentic AI systems focused on resilience, automation, and intelligent orchestration.
Building the future of autonomous AI systems — one resilient architecture at a time.
🚀Ready to build AI-first?
I am continuously architecting, building, and documenting production-ready AI ecosystems. If you resonate with this direction and want to scale your ideas, let's initiate a connection.